
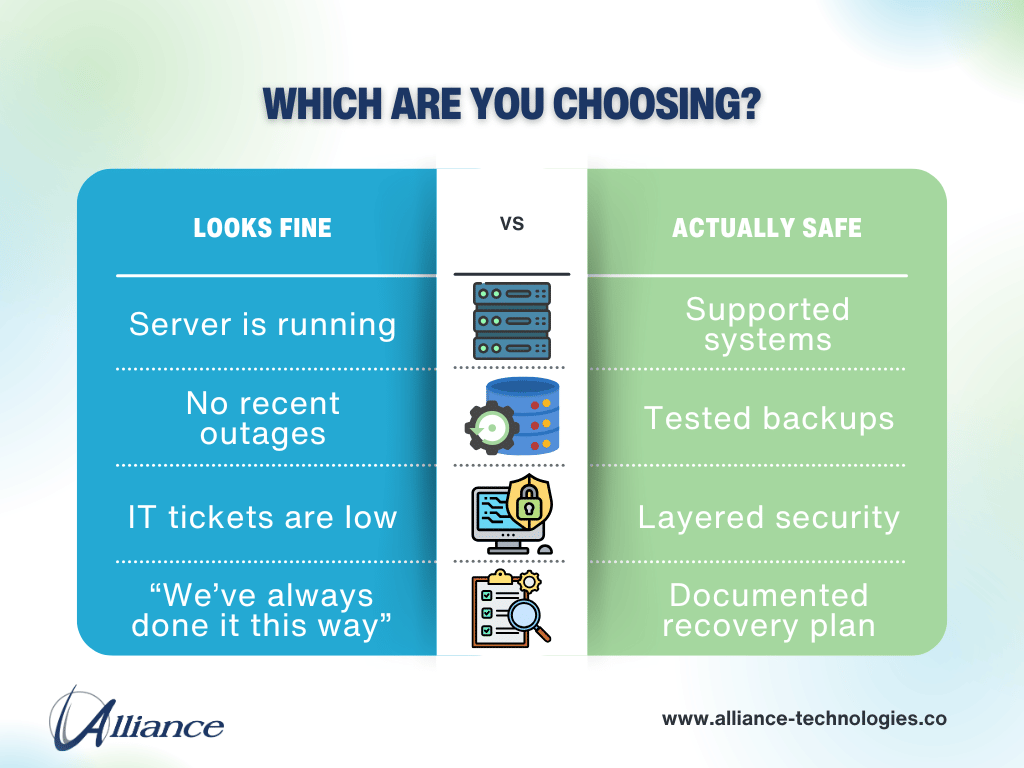
- Many businesses assume their IT is safe because “nothing has gone wrong yet,” but that’s often a false sense of security.
- Business disruptions rarely come from a cyberattack itself. They start with systems that were “good enough” for too long.
- The real risk isn’t broken technology. It’s technology you’ve learned to trust without questioning.
Your IT environment probably doesn’t look broken.
Employees can log in. Email works. Files open. The server is still running.
From the outside, everything appears fine. But that’s exactly what makes it dangerous. But for many leaders, the real challenge isn’t broken systems—it’s understanding where their environment actually sits on the IT maturity curve.
Both environments can look stable. Only one is built to hold up when conditions change.
The Comfort of “It’s Still Working”
One of the most common things we hear from leadership teams is a simple, reasonable question:
“If it’s working, why would we change it?”
After all, technology upgrades cost money. They require planning. They introduce disruption. When nothing seems wrong, it’s easy to justify leaving things as they are.
The problem is that “still working” isn’t the same as being secure, resilient, or prepared.
A better way to think about it is like this: imagine a water heater that was installed decades ago. It still heats water. It hasn’t leaked. It hasn’t caused a problem…yet.
But no one would argue that it’s a safe long-term plan.
Not because it’s broken, but because when it fails, it will fail suddenly. And when it does, the damage will be immediate, expensive, and disruptive.
That’s the reality for many IT environments today—not broken, just running on borrowed time.
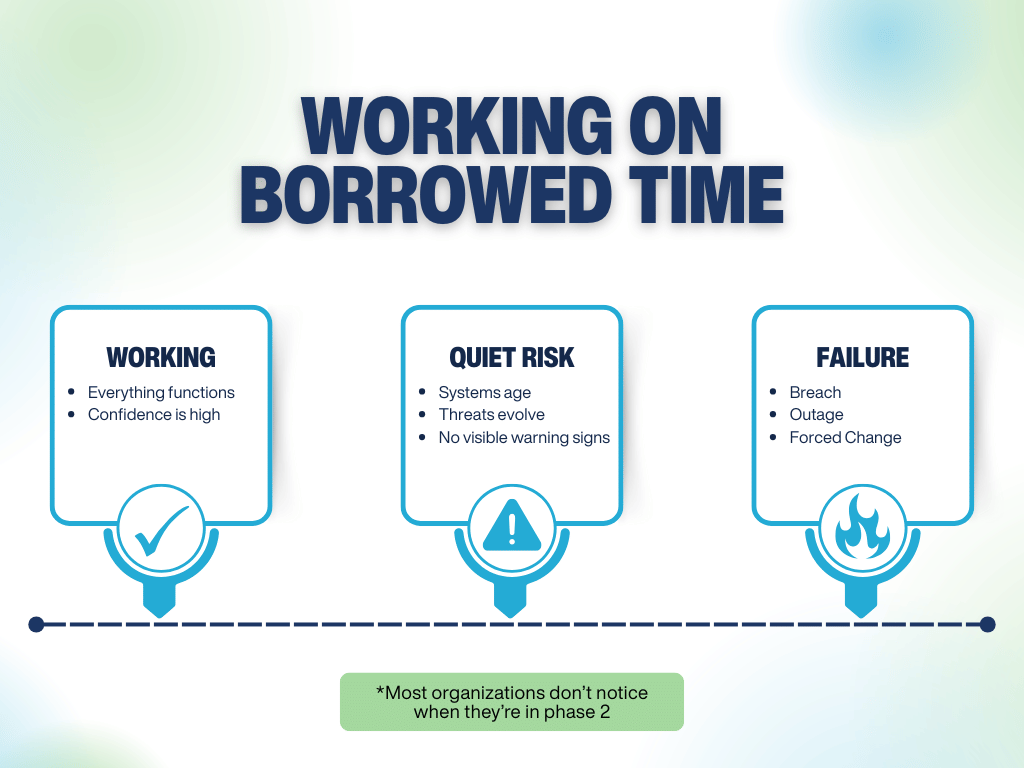
“Still working” is often the longest, and riskiest, phase of an IT environment, but most IT environments don't fail suddenly —they age quietly until change is forced.
When Stability Is Actually Fragility
We regularly see organizations relying on systems that are far past their intended lifespan. Servers that no longer receive vendor support. Security tools that were implemented once and never revisited. Backups that exist in theory but haven’t been tested.
From a day-to-day perspective, things feel stable, but modern cyber threats don’t wait for systems to show signs of failure. They quietly look for outdated systems, weak configurations, and unpatched software, turning apparent stability into risk.
In these environments, the absence of incidents is often mistaken for proof of safety. In reality, it’s usually just luck.
And luck doesn’t scale.
Familiarity Can Be a Liability
Another reason fragile IT environments persist is familiarity. Teams know the systems. They’ve learned how to work around limitations. They’ve adapted to quirks that no longer even register as problems.
Change feels risky. Staying put feels safe.
But that sense of safety can be misleading.
Legacy systems don’t usually fail in small, manageable ways. They fail abruptly, like when something external changes. Vendor support ends. Security standards evolve. Compliance requirements tighten. New attack methods outpace old defenses.
When that happens, organizations aren’t choosing change anymore. They’re reacting to it. But many organizations don’t need a full overhaul; they need better visibility and support around what already exists.
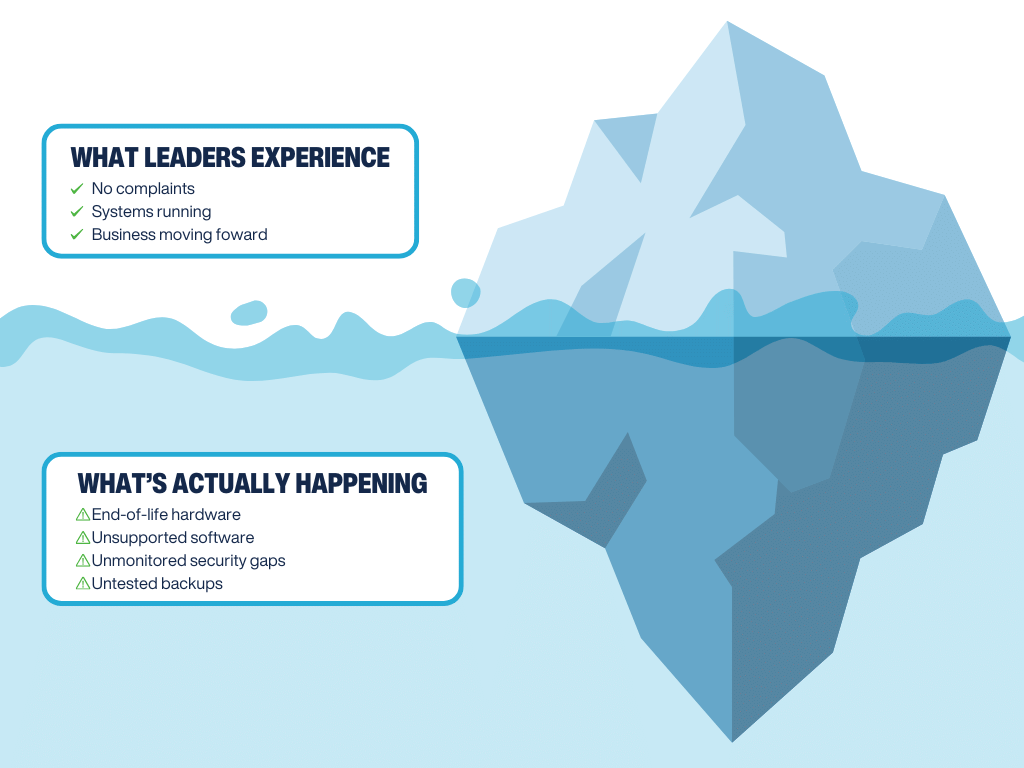
No complaints doesn’t mean no risk. It usually means no visibility.
Fear of Change vs. Cost of Waiting
Many leaders delay IT improvements because they’re worried about disruption, downtime, or losing control. Those concerns are understandable, especially if past technology changes were painful.
But waiting until change is forced on you almost always creates more disruption, not less. These fragile IT systems don’t just increase the risk of downtime; they can also delay product launches, complicate audits, stall M&A due diligence, and erode customer trust. What looks like a technical debt issue right now becomes a costly roadblock tomorrow. When IT isn’t future-ready, neither is the business.
Proactive IT isn’t about ripping everything out or chasing trends. It’s about making intentional decisions before risk turns into impact. Replacing aging systems before they fail. Adding layers of protection instead of assuming existing ones are enough. Building redundancy so a single issue doesn’t halt operations.
It’s the difference between steering the business forward and scrambling when something breaks.
Asking the Right Question
As a business leader, you don’t need to manage servers or patch software, but you do need to know whether aging infrastructure could jeopardize operations, compliance, or growth plans. You can’t delegate accountability for outcomes, even if you delegate the technical details.
Instead of asking, “Is our IT broken?” a better question is:
“If this fails tomorrow, what happens to the business?”
If the answer includes extended downtime, lost revenue, customer impact, regulatory exposure, or leadership scrambling for answers, then the risk already exists, even if everything appears to be working today.
Resilient organizations don’t wait for a failure to justify action. They address risk while they still have options.
IT as Readiness, Not Reaction
The healthiest companies treat IT as a core business system, not background infrastructure. They plan for transitions before they’re urgent. They test assumptions instead of trusting them. They invest with intention rather than reacting under pressure.
The goal isn’t to avoid change forever.
It’s to change on your own terms.
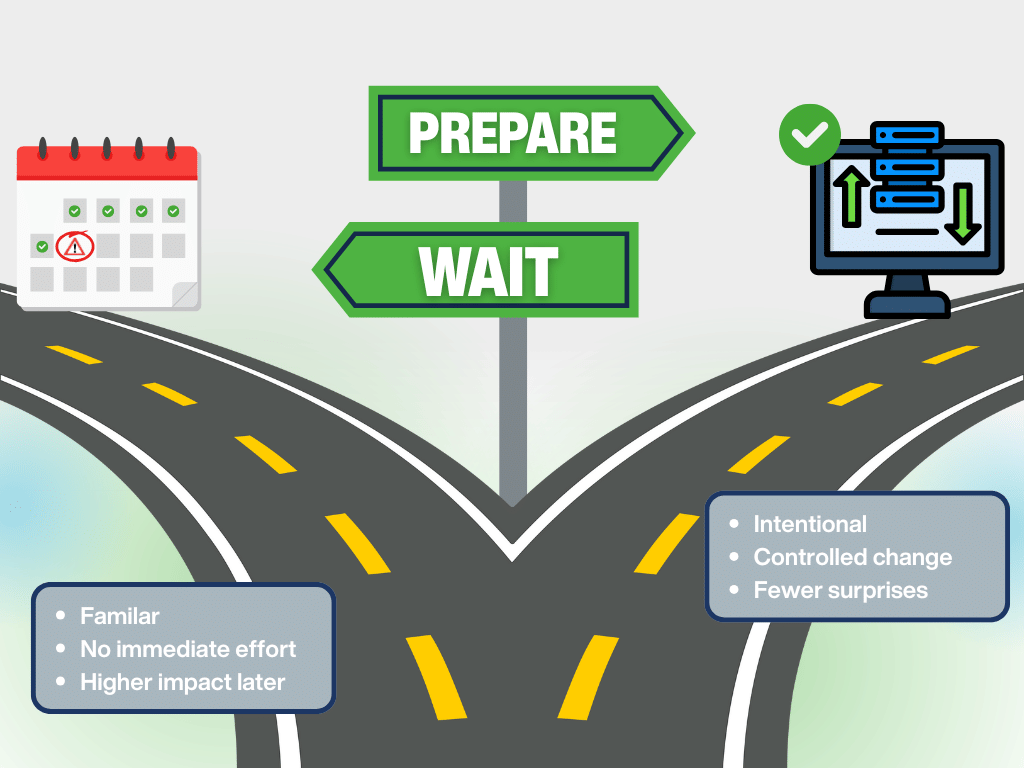
Both paths feel comfortable at first, but they don't lead to the same outcome. While waiting may avoid effort today, preparing avoids disruption later.
Your IT Doesn’t Have to be Broken to be Dangerous
If it’s aging, unsupported, under-secured, or held together by workarounds, it’s already introducing risk into the business, whether that risk feels immediate or not.
Running on borrowed time often feels comfortable.
Until it isn’t.
Not Sure If You’re Safe or Just Lucky?
If your IT “works,” but you’re not sure how exposed you really are, a quick risk reality check can help clarify what’s actually secure, what’s aging quietly, and where the real vulnerabilities live.
No disruption. No pressure to change anything. Just a clear picture so you can decide what’s next on your terms.
Prefer to start on your own?
Take our 3-minute IT Risk Snapshot to get a quick sense of where you stand.
Take the Quick Quiz

